



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
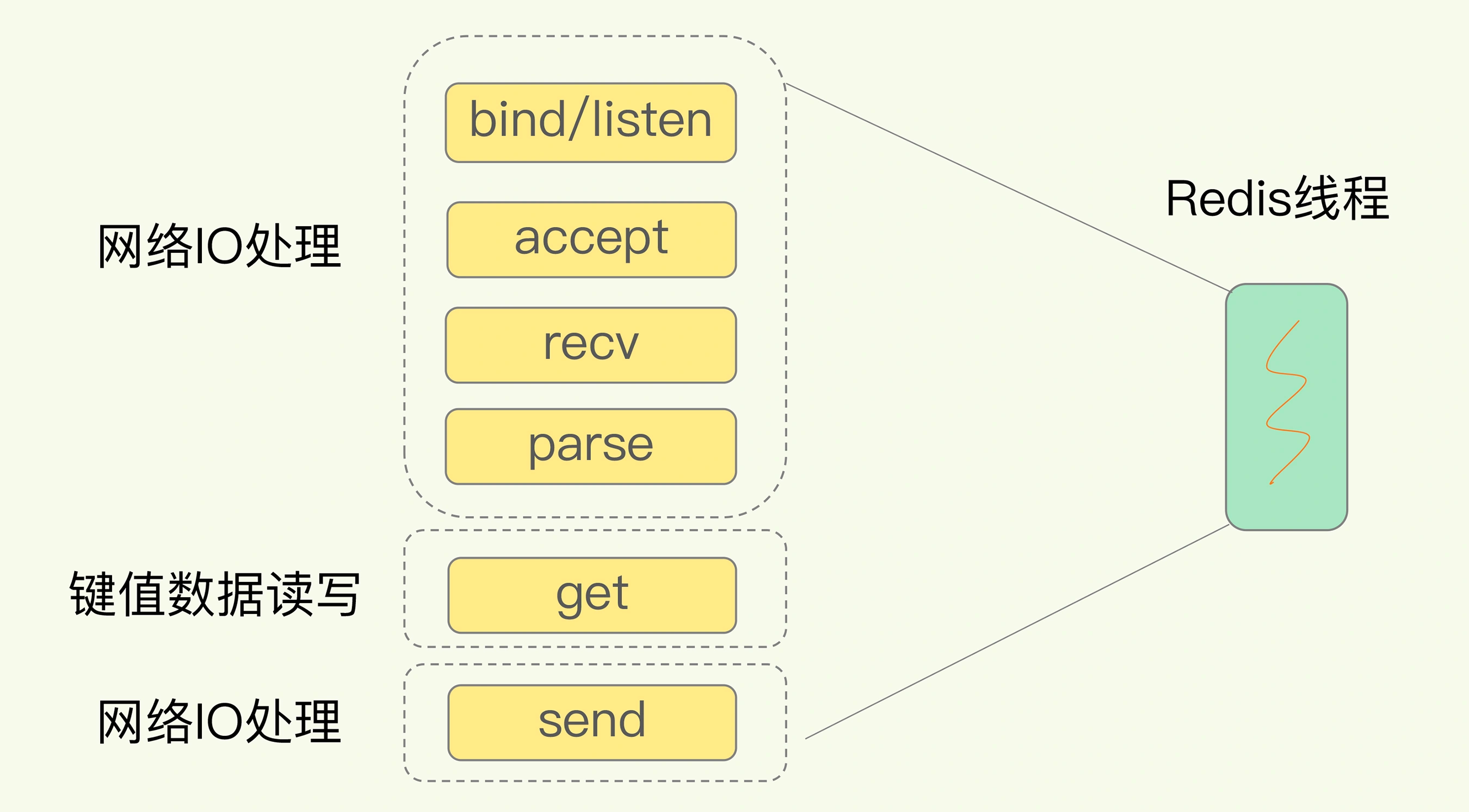
Redo-log Master-Slave Data Synchronization
Please provide a clear and accessible explanation of how master-slave synchronization using Redo Log can improve data management and storage, with relevant real-world examples. And what is the difference, advantages and disadvantages between binlog master-salve data synchronization and redo log master-salve data synchronization?
Please also include relevant resources or tips for further learning on this topic, such as reputable sources and recommended reading.
Please note that your response should encourage creative and flexible thinking about the concept of master-slave synchronization, while still providing a solid foundation of understanding and step-by-step guidance.
Concept
Master-slave synchronization with Redo Log involves capturing and applying the changes made to a database's Redo Log files. The Redo Log records the data modifications (inserts, updates, deletes) performed on the master database. By replicating the Redo Log from the master to the slave databases, the same modifications are applied to the slave databases, maintaining data consistency in the same order they occurred on the master.
Comparing with the Binlog Master-Slave Data Synchronization
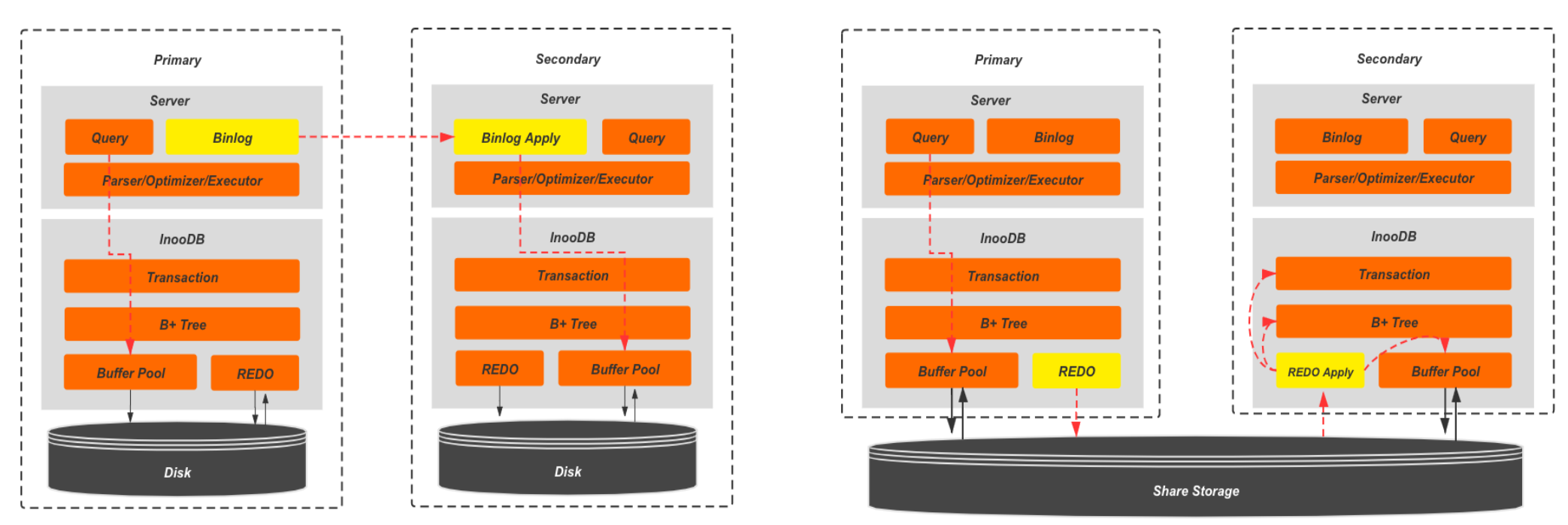
This image is from Baotiao's comparison of PolarDB and MySQL redolog and binlog, assuming here that the cluster using redolog is ShareStorage. So the logical replication has more delay than the physical replication.
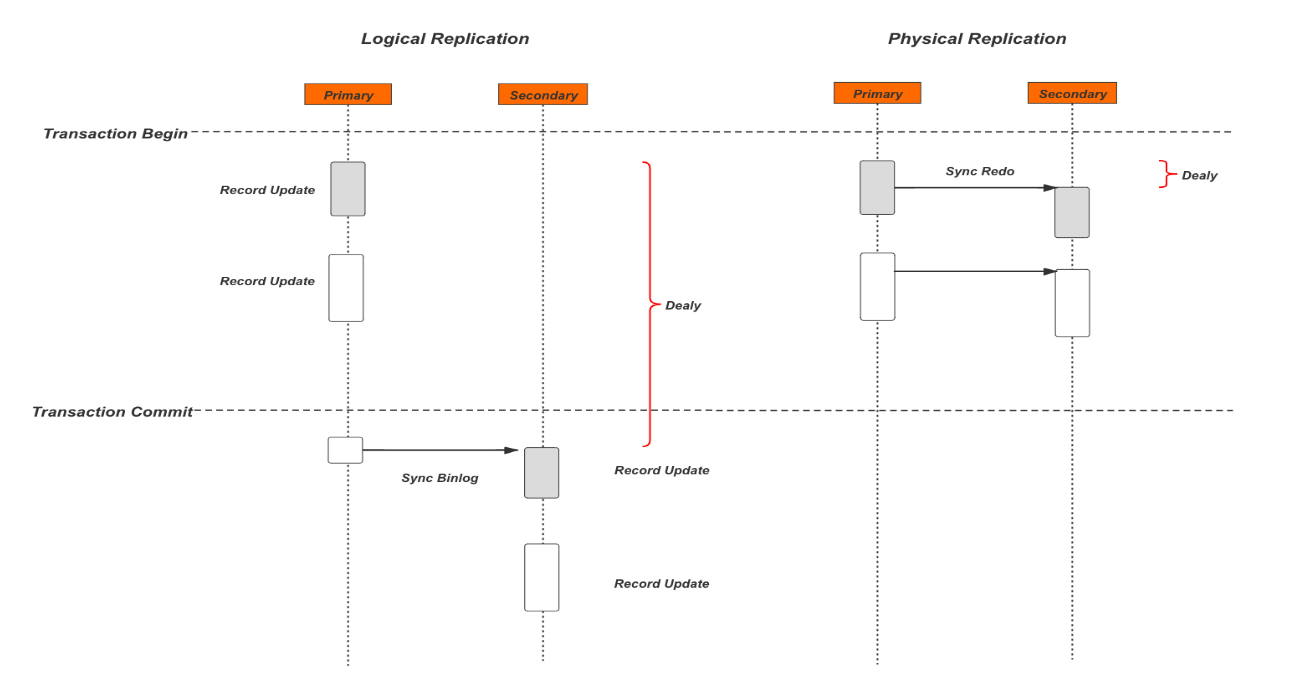
Advantages:
- Lower Network Overhead: Redo log replication transmits only the physical changes made to the database, resulting in reduced network traffic compared to binlog replication.
- Higher Transaction Durability: Redo log replication captures the changes at the physical level, ensuring that even if the master crashes, the slave(s) can recover the data changes and maintain data integrity.
- Faster Synchronization: Redo log replication can be faster in synchronizing the data changes between the master and slave(s) due to its efficient capture and apply mechanism.
Disadvantages:
- Physical Replication: Redo log replication operates at the physical level, making it less flexible for replicating to different databases or database versions.
- Limited Point-in-Time Recovery(Rollback?): Redo log replication does not provide a point-in-time view of the executed SQL statements like binlog replication. Recovery is based on physical changes, making it less precise for point-in-time recovery scenarios.
- Complex Schema Changes: Redo log replication requires additional considerations and techniques for handling complex schema changes, such as table alterations involving large amounts of data.
In summary, binlog master-slave data synchronization offers logical replication, point-in-time recovery, and ease of schema changes, while redo log master-slave data synchronization provides lower network overhead, higher transaction durability, and faster synchronization. The choice between these approaches depends on the specific requirements, data characteristics, and priorities of the database system.